…………
leetcode-4.Median of Two Sorted Arrays
There are two sorted arrays nums1 and nums2 of size m and n respectively.
Find the median of the two sorted arrays. The overall run time complexity should be O(log (m+n)).
You may assume nums1 and nums2 cannot be both empty.
理解RESTful架构
起源
REST这个词,是Roy Thomas Fielding在他2000年的博士论文中提出的。

Fielding是一个非常重要的人,他是HTTP协议(1.0版和1.1版)的主要设计者、Apache服务器软件的作者之一、Apache基金会的第一任主席。所以,他的这篇论文一经发表,就引起了关注,并且立即对互联网开发产生了深远的影响。
5-21学习小结
Normal equation
标准方程能够快速计算(在n相对较小的情况)出θ的值不需要迭代。
| Gradient Descent | Normal Equation |
|---|---|
| Need to choose alpha | No need to choose alpha |
| Needs many iterations | No need to iterate |
| O (kn^2 ) | O (n^3), need to calculate inverse of X^T*X |
| Works well when n is large | Slow if n is very large |
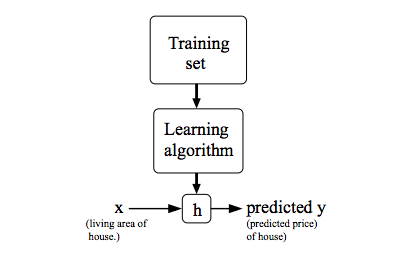
5.2学习小结
Supervised learning
- 给algorithm一个data set in which “right answers” given
- Regression: predict continuous valued output
- Classification = discrete valued output(0 or 1)
Unsupervised learning
- just give algorithm a data set nothing else(no extra information)不知道数据集的意义
- clustering algorithm 聚合算法
- Cocktail party problem 鸡尾酒会算法
- Octave
diabetes
Bachelor, Master and Doctor
BA: 文学学士学位(Bachelor of Arts)
BBA: 工商业管理学士学位(Bachelor of Business Administration)
BS: 理学学士学位(Bachelor of sciense)
MA:文学硕士学位(Master of Arts)
MS:理学硕士学位(Master of Sciense)
MBA:工商管理硕士学位(Master of Business Administration)
PhD:哲学博士学位,文理科均可。(Doctor of Philosophy)
python简单爬虫爬取豆瓣影人照片
1 | # -*- coding: utf-8 -*- |